Real Estate Web Design - Information
|

|
Information Request
I would like to see a real site (and pricing) as well as information on availability for my area for lead generation.
|
|

|
|
|
GENERATE LEADS
LEARN MORE >>
First: We create an incredible website, breaking out up to 700 communities/suburbs/subdivisions, each with its own page!

Second: We offer TWO options for our clients. One allows you to simply post (or have us do this for you) to Craigslist a high impact flyer generated by any search on your site! What this means is that you can create searches in various popular areas, at price ranges you know are popular. We even allow you to create flyers based on FORECLOSURES / HUD / SHORT SALES etc!
This allows you to generate leads by your own SWEAT EQUITY! You aren't tied to a large monthly bill to generate leads! We're the only company on the internet that offers this!

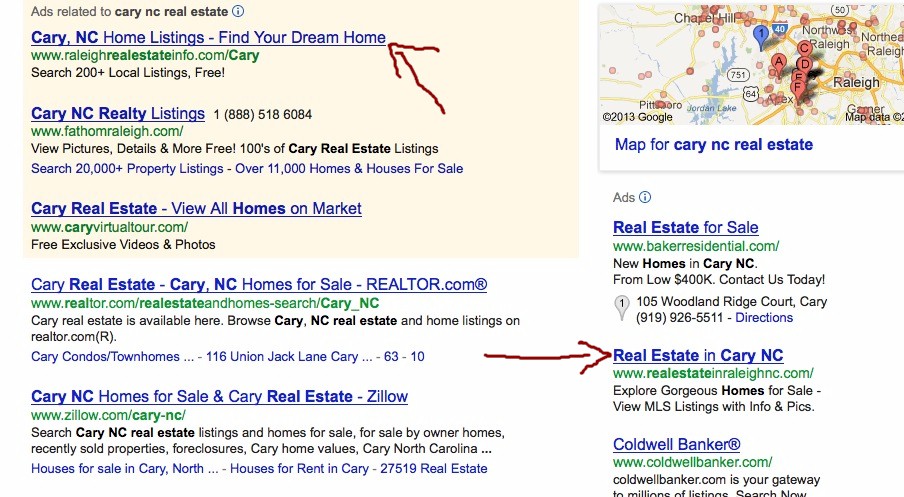
Optionally: Adwords - We CREATE for you up to 1200 ADS (Each with over 40 keyword phrases) for up to 400 communities/neighborhoods/subdivisions Each with its own landing page! No more wasting money on clicks that go to a generic page that isn't really what the client wants! We drive the client to the page they were looking for so you generate a lead for about every 7-9 clicks! (on average)
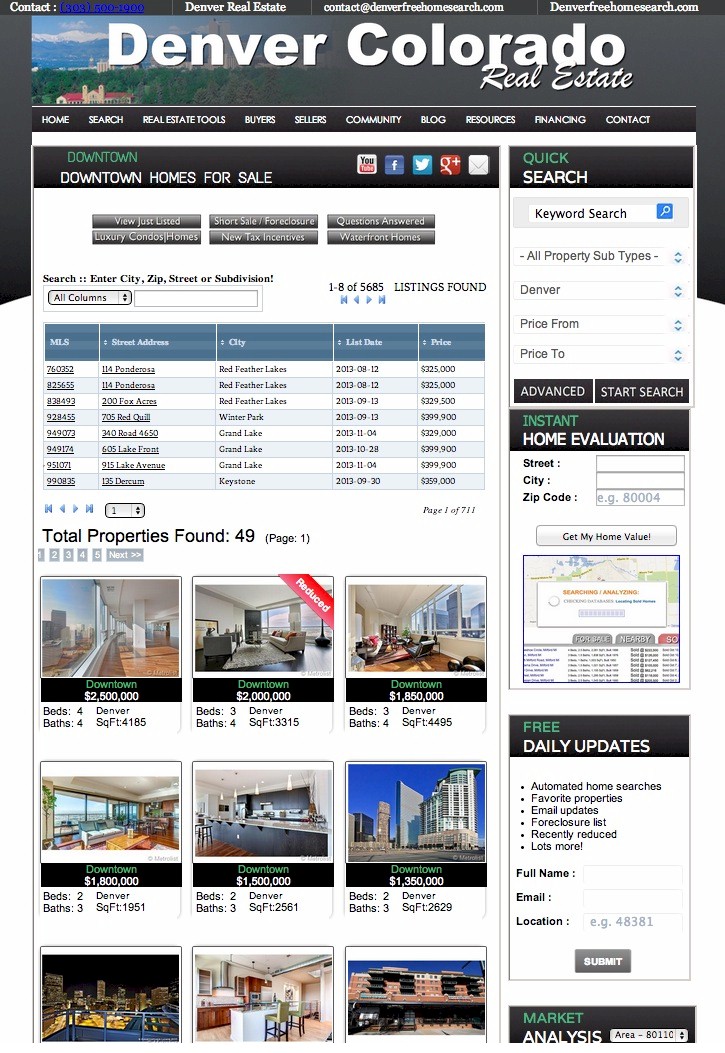
Third: We drive incoming traffic (potential clients) to a high impact (lead generating page) with lots of useful information and methods to capture leads Like View Just Listed, View Foreclosures, Answer a Question, Recently Reduced, Hot List and More!
 Finally: Once your generating leads (Day 1 if you're posting to craigslist!) You'll have a robust back end CRM system that will allow you to effectively manage your leads. Each time the visitor returns, they'll get an email thanking them for their return visit with different content written for each visit. You'll be able to see each page they visited and how long they stayed on each page. Advanced traffic analysis will let you know how many daily visitors you're receiving, which search engines are driving traffic to you and what keyword phrases are being used to find our site organically!
Finally: Once your generating leads (Day 1 if you're posting to craigslist!) You'll have a robust back end CRM system that will allow you to effectively manage your leads. Each time the visitor returns, they'll get an email thanking them for their return visit with different content written for each visit. You'll be able to see each page they visited and how long they stayed on each page. Advanced traffic analysis will let you know how many daily visitors you're receiving, which search engines are driving traffic to you and what keyword phrases are being used to find our site organically!
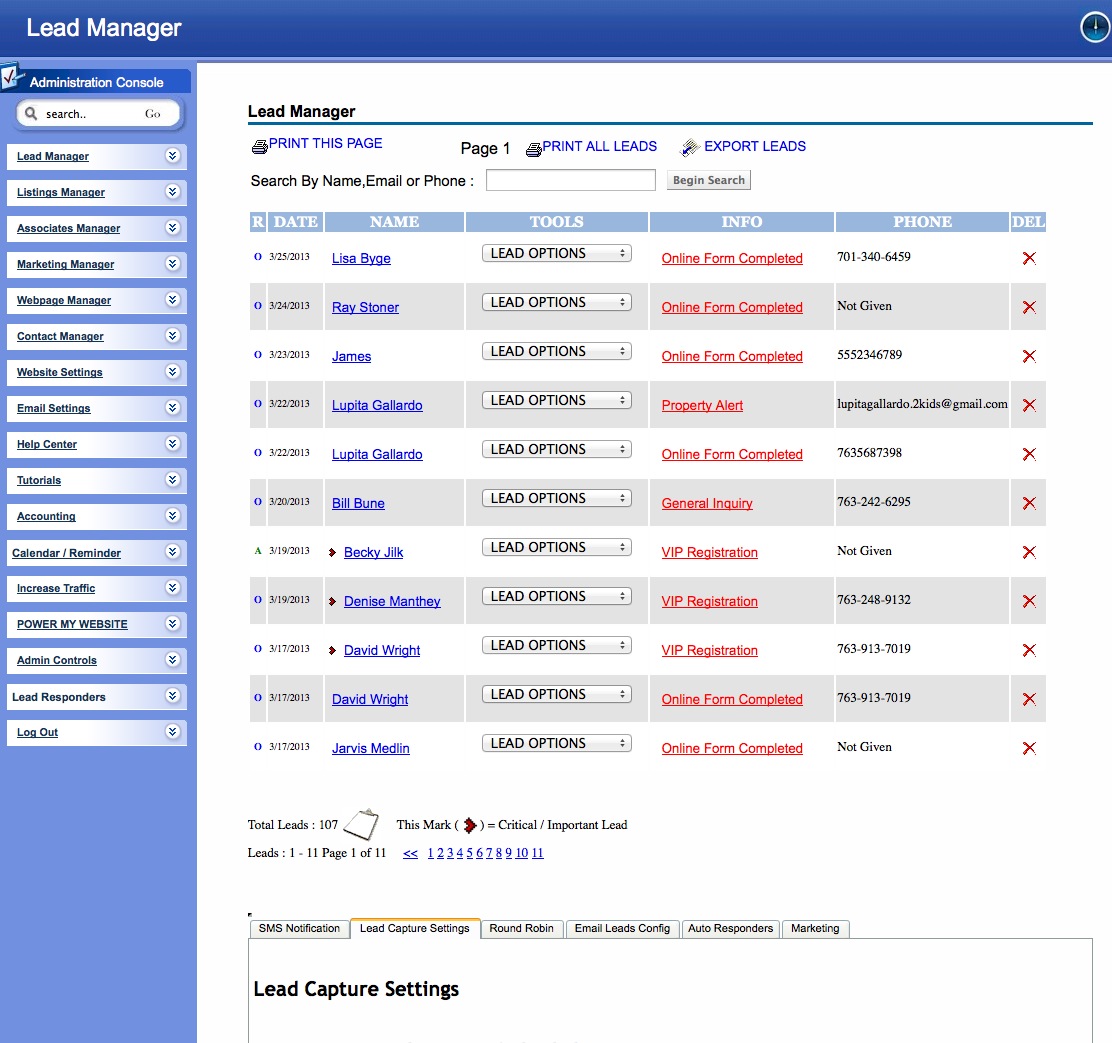
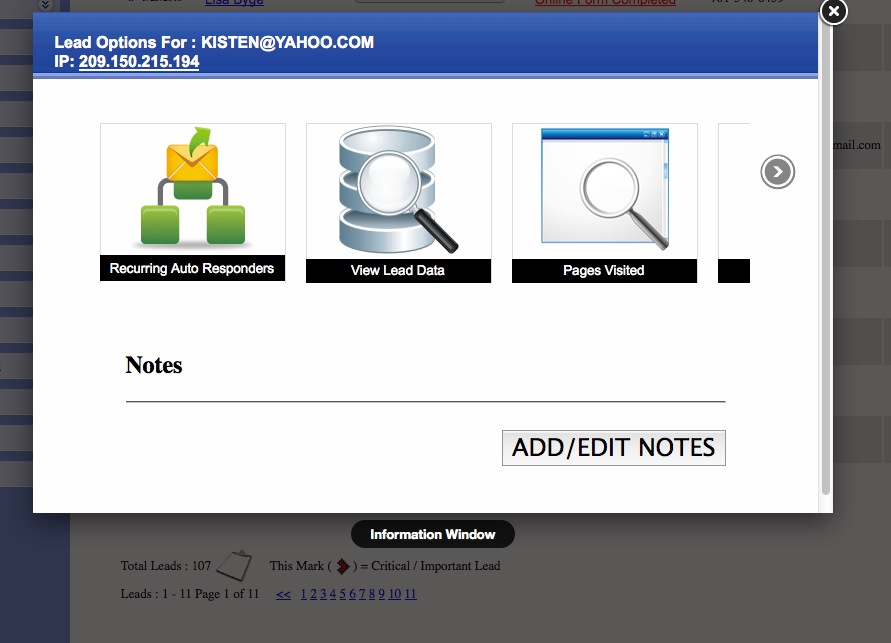
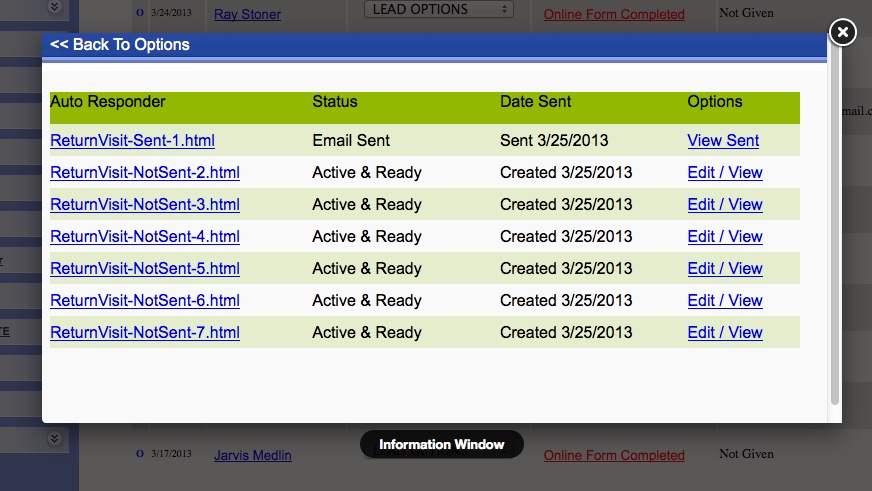
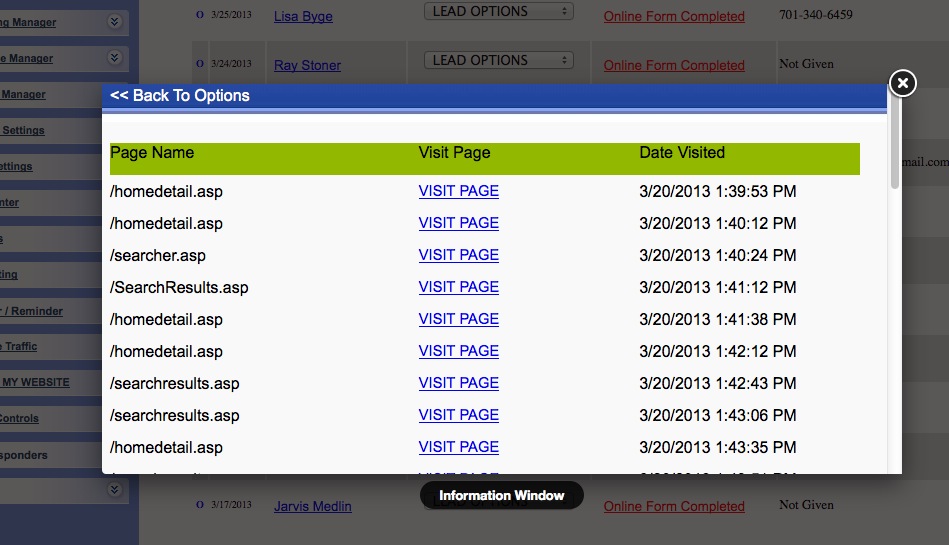
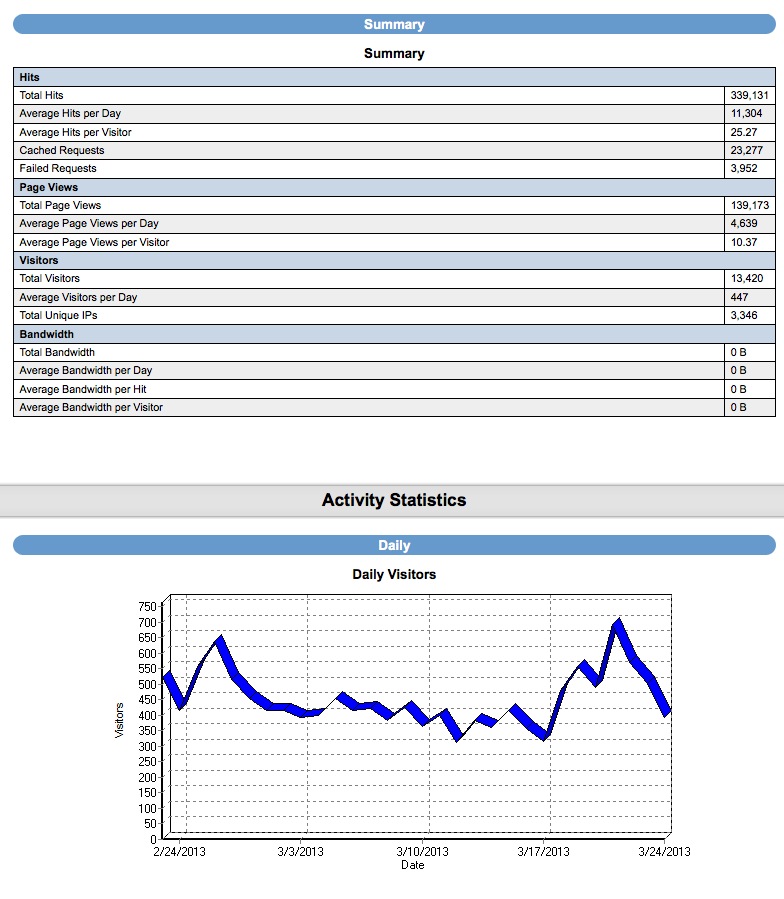
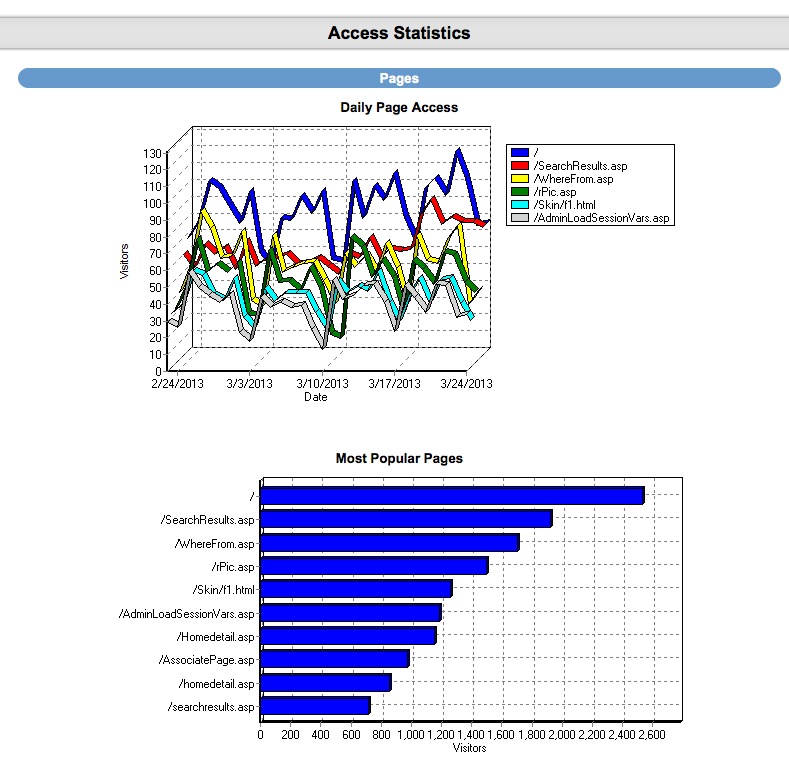
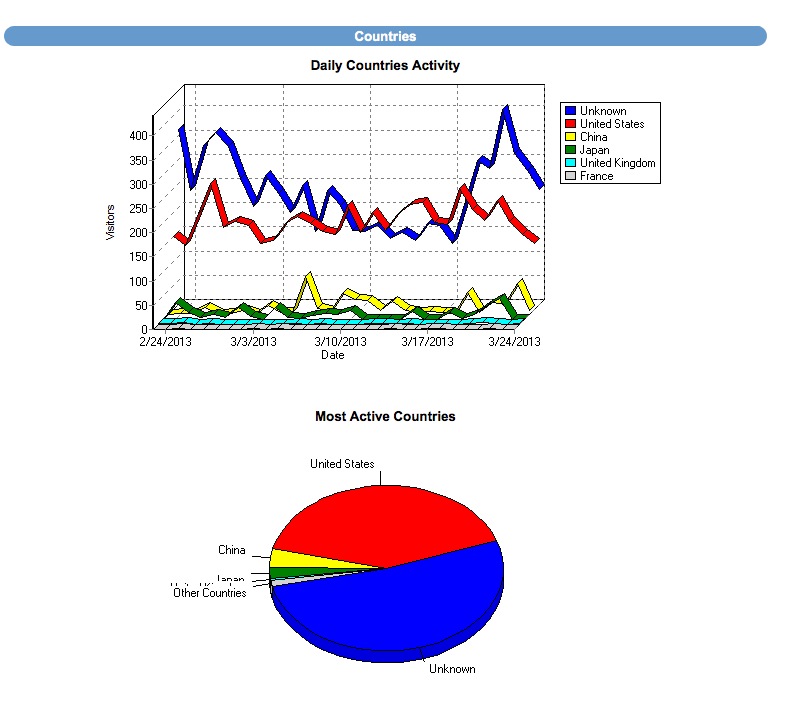
CRM also includes: Email Drip Marketing, Client login portal with saved listings, email a friend, private communication message base and document file system. Broker round robin sysetm is also built in! There are too many features to mention!
|
|
|
|
|
|
|
|
|
|
|
|
Top SEO Techniques
- Link Building - Quality Inbound Links
- Proper Text / Keyword Density (Title, Heading and Meta Tags)
- Image Tag Attribution
- Relavant Text Links
- Robust, regularly updated XML Sitemap
- Relavant, Consistant Content
- Easy Blogging (Our system will ask you questions)
- Social Media Hooks and Youtube Video Hooks
|
|
|
|
|