|
|
- Real Estate Web Design
- Lead Generation
-
Real Estate Plugins
-
Free Widgets
Lead Capture Home Evaluation Live SMS Chat Area Info -
For Pay Widgets
Enterprise SMS Chat Advanced Home Evaluation Lead Capture & Keylogging IDX Search IDX Broker Signup -
Design Upgrades
For IDX Broker Sites For Wordpress Sites
Generate Prospects Qualify Prospects Nurture Prospects Close Hot LeadsSales Funnel -
Got An Idea? If You've Got The Money - We Have The Time!

Plugins, Snapins, Extensions
After 15 years of programming we have assembled an assortment of tools that can now be installed on third party websites! Chat, Statistics, School info, Mapping with boundaries and so much more!
-
- How To | Answers
- Content
Great Things Await!
Our customers enjoy premium content! Enter your password to proceed!
Enter Your Customer Password

CLICK ANY DESIGN FOR MORE INFORMATION
LET US EMAIL YOU MORE INFORMATION


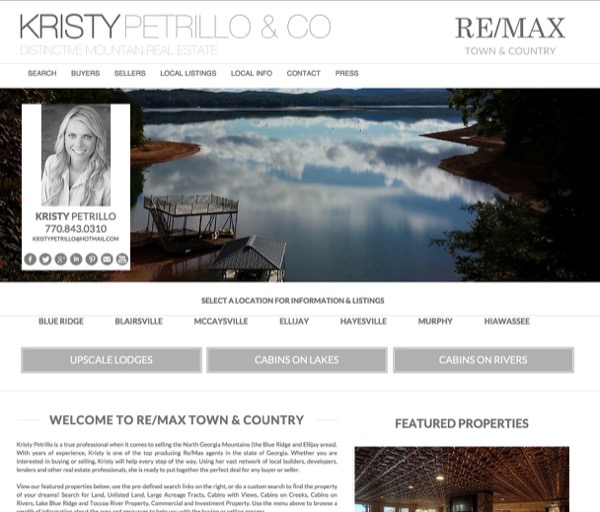
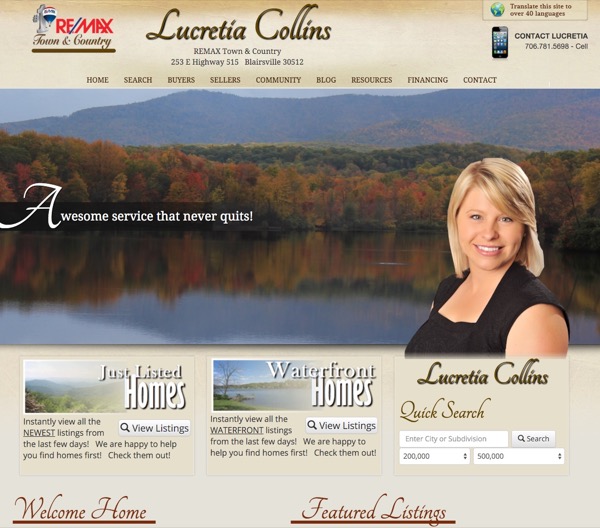
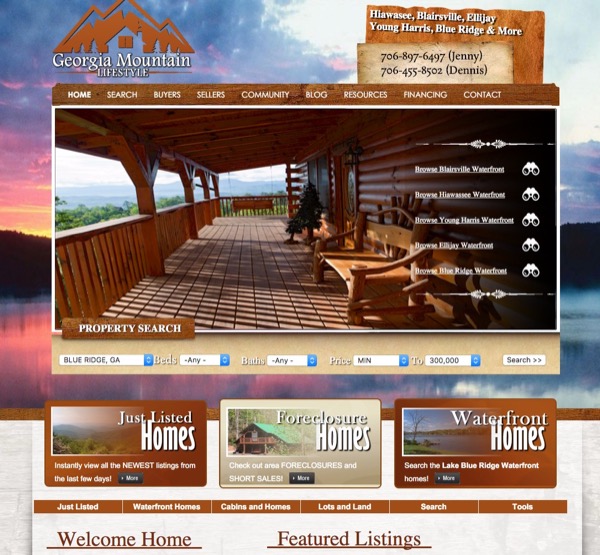
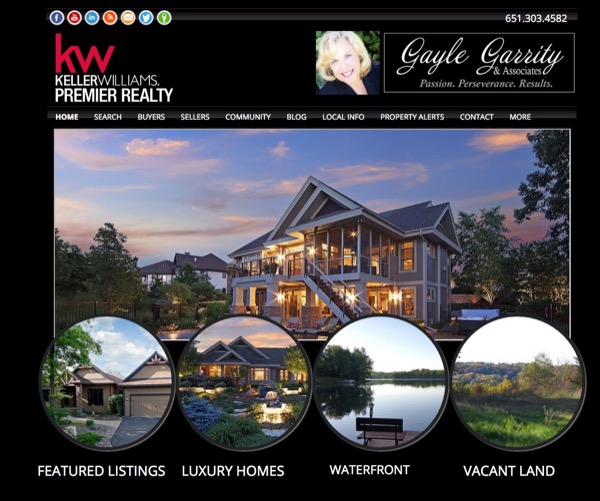

We generate traffic via organic, social or paid placement ads through Facebook, Google, Bing and others! Effective "Calls To Action", that is, compelling reasons for someone to give you their contact info and more importantly, willing to trust that you are able to help them with their needs! At the end of the day, you are able to help people with their problem which is finding the home they are looking for, in the place they want to be at a price they can afford!
Recent posts
Lead Generation
Template Library
Contact Us
Privacy Policy | | | Terms and Conditions |